
概 况
在《采纳率从 7.9% 到 54%:快手智能 Code Review 的三阶进化》中,快手研发效能团队重点分享了智能代码审查系统如何通过质量过滤与知识沉淀,将 AI 能力嵌入研发交付链路,使其从个人辅助工具升级为团队级的协作生产力。但要真正实现从“个人提效”到“组织效能”的闭环,仅优化代码合并前的质量关口仍然不够,AI 能力还需要进一步向研发流程的前后环节延展。
在全面推进「AI 研发范式升级」的进程中,如何将个人 AI 工具的零散提效沉淀为组织级的交付能力,是当前效能升级的核心命题。在需求评审之后、测试执行之前,用例设计这一关键环节,正是影响交付质量与效率的另一瓶颈。围绕这一问题,我们构建了智能用例生成系统,实现从手动编写到审核校验的模式转变,这种转变不仅释放了测试人员的构思压力,更让 AI 升级为流程中稳定、可信的生产力环节。
以往写用例全靠人工硬磨,效率低且难保全。为此,快手研发效能团队复盘了智能用例生成系统的演进路径,总结了快手智能用例生成系统从「Prompt 工程探索」到「Multi-Agent 人机协作」,再到「知识增强策略」,最终走向「自检测 & 自进化」的四阶架构演进。
针对生成质量不稳、业务理解浅、维护成本高这三大难题,我们通过「人机协作」兜底质量、「知识工程」对齐业务场景、「自检测 & 自进化」降低人工维护负担。这套思路直接将用例生成率从 8% 拉升至 60%+,累计生成测试用例逾 120 万条;该系统已经成为全公司测试人员日常使用的标准化生产力工具,真正跑通了从个人 AI 提效到组织交付效能提升的闭环路径。

背 景
在快手持续推进研发效能提升的过程中,我们对测试阶段各环节的耗时进行了深入分析,测试用例设计阶段(即测试用例编写阶段)在整个测试周期中占据了 13.69% 的时间成本,与用例执行、回归测试并列为耗时最高的三大环节;这一数据揭示了传统测试模式下的瓶颈:测试人员将大量精力投入在重复性的用例撰写工作中,而非聚焦于更具价值的测试策略设计和缺陷挖掘。
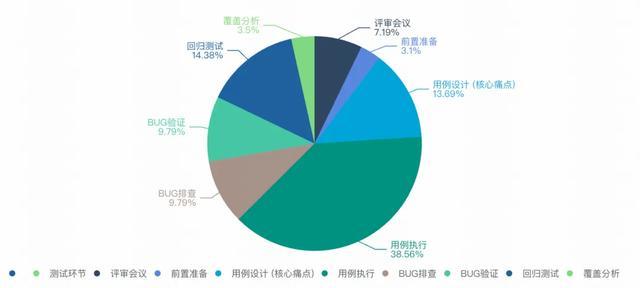
在用例设计提效方面,快手此前主要通过 KCase 平台的用例编写在线化能力进行优化。该方案实现了用例模板的规范化与标准化、多人协作编辑与版本管理、用例资产的结构化沉淀。
然而,这种模式本质上仍依赖人工逐条编写,效率提升存在明显天花板。面对快手业务的高速迭代和海量的功能需求,测试团队面临以下挑战:

2023 年以来,以 GPT 系列为代表的大语言模型(LLM)在代码理解、逻辑推理和文本生成方面实现了质的飞跃。快手质量工程团队敏锐捕捉到这一技术拐点,从 2024 年正式开始启动 AI 生成手工测试用例的探索项目,目标是将「人工编写」升级为「AI 生成 + 人工审核」的全新模式,释放测试人员的生产力。
效 果
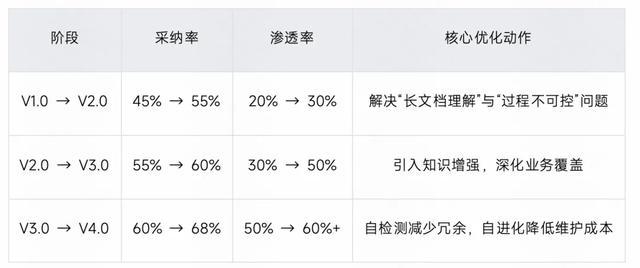
快手智能用例生成系统从 V1.0 到 V4.0 的演进历程,涵盖从初期的 Prompt 工程探索(生成率 8%),到 Multi-Agent 人机协作模式(生成率 12%),再到知识增强策略(生成率 35%),最终通过自检测与自进化实现突破性提升(生成率超 60%)。目前,该系统已在快手实现公司级 60% 以上的用例生成率,累计生成测试用例逾 120 万条。
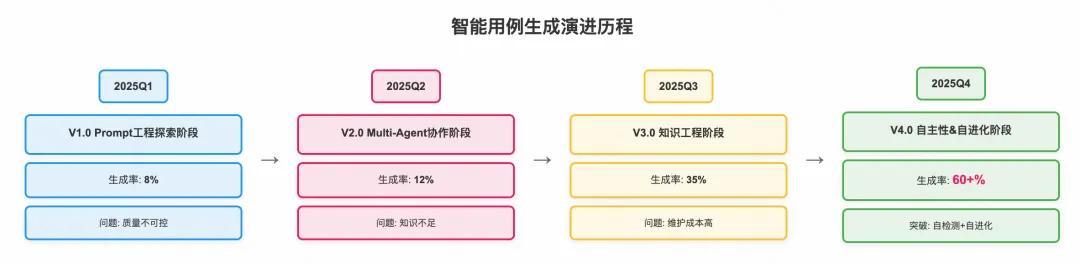
从 8% 到 60%+ 的生成率跃升,体现了快手技术理念的持续演进:
V1.0:验证了“AI 能够生成测试用例”的可行性
V2.0:确立了“人机协作生成优于纯自动化生成”的实践路径
V3.0:揭示了“知识比算法更关键”的本质规律
V4.0:实现了“AI 自我进化”的能力突破
我们不再纠结于 AI 是否能够替代人类,而是为“AI 如何赋能人类更高效工作”寻求解法。
实践 1:从 V1.0 到 V4.0 的技术架构演进实践
3.1 V1.0 版本:Prompt 工程探索阶段
3.1.1 初版设计思路
核心假设:大模型已具备足够的“测试常识”,只需通过精心设计的 Prompt 引导,即可生成高质量测试用例。
技术方案:V1.0 单体生成流程

3.1.2 核心技术实现
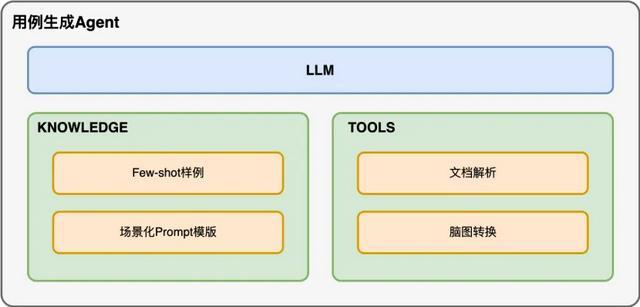
Prompt 结构设计
初版 Prompt 架构
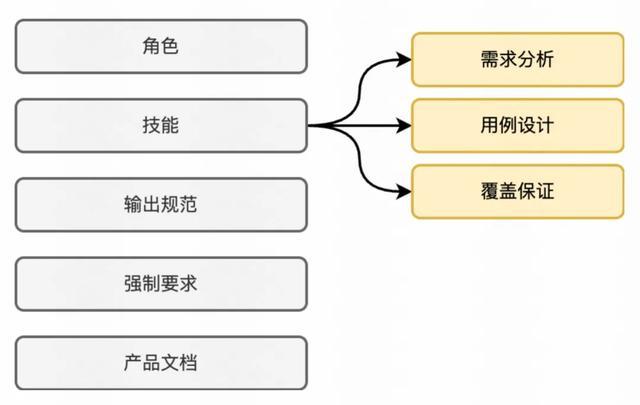

第一轮优化:Few-shot Learning
问题分析:生成的用例质量仍参差不齐,主要原因是模型对“高质量用例”的标准理解不足。
解决方案:引入来自业务真实场景的高质量测试用例作为样本,提升模型输出的一致性和专业性。
Few-shot Prompt 架构:
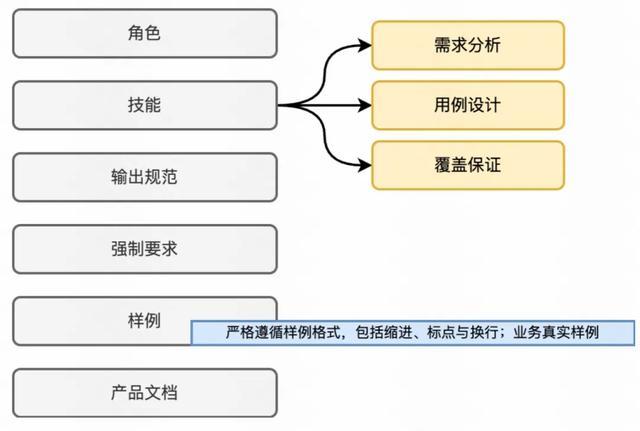
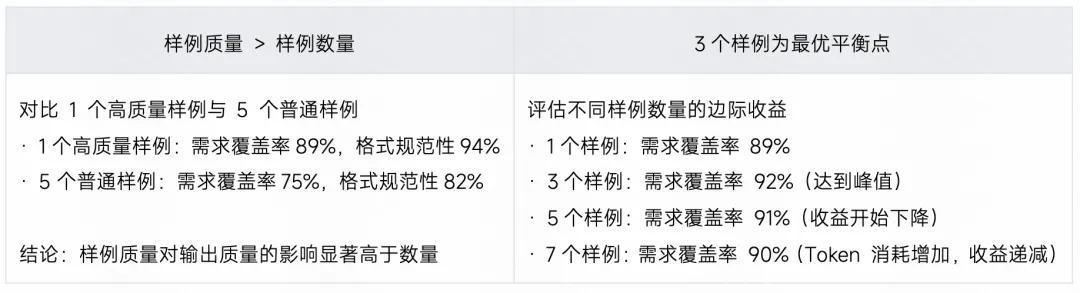
关键发现:
提供 3 个样例为性价比最优选择(边际收益趋于平缓)
样例质量远重于数量(1 个高质量样例 > 5 个低质量样例)
实际生成效果对比:

第二轮优化:场景化 Prompt 模板
问题分析:不同类型的需求文档(如 PRD、技术方案 等)需要匹配差异化的测试策略,通用 Prompt 难以覆盖多样化测试目标与表达要求。
解决方案:构建多场景路由机制,依据输入文档的类型自动匹配最优的 Prompt 模板,实现精准化、专业化测试用例生成。
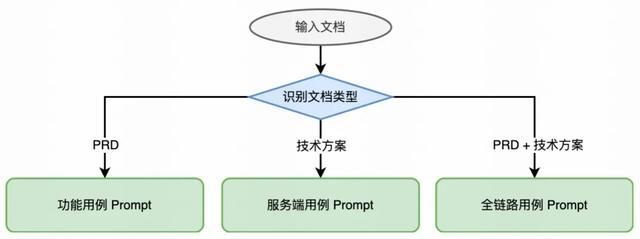
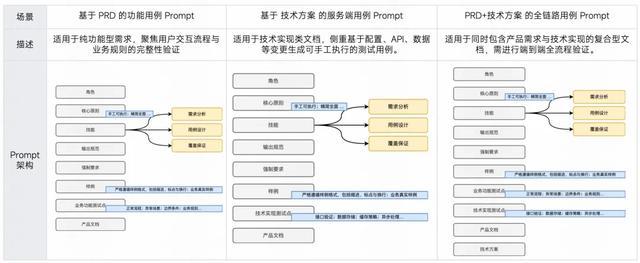
3.1.3 效果测评
为了验证 Prompt 优化策略的有效性,我们针对多个关键动作开展了系统性测评。测评基于真实业务场景中的 PRD 和技术方案文档,采用统一测试集进行对比评估。
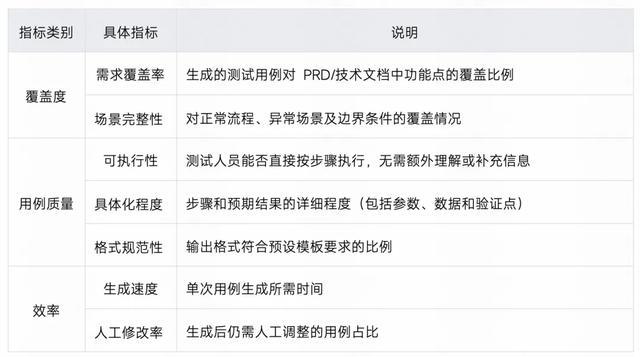
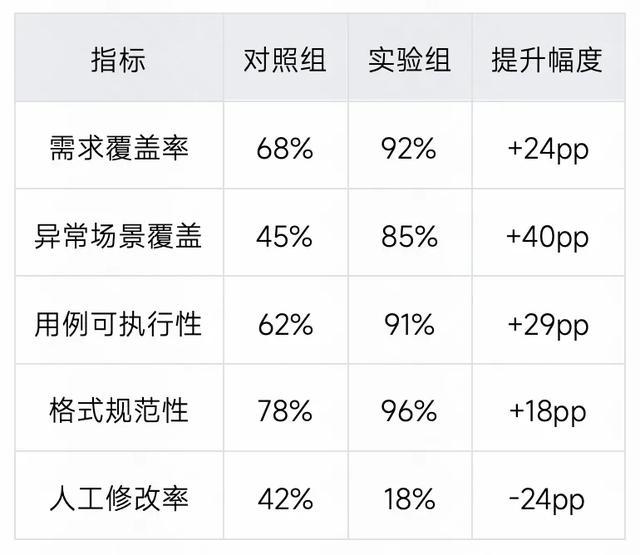
测评一:Few-shot Learning 效果验证
测试场景: 基于 PRD 生成功能测试用例(礼物贴纸玩法模块)
对照组: 无 Few-shot 的初始版本 Prompt
实验组:引入 3 个高质量样例的 Few-shot Prompt
测评二:场景化 Prompt 模板效果验证
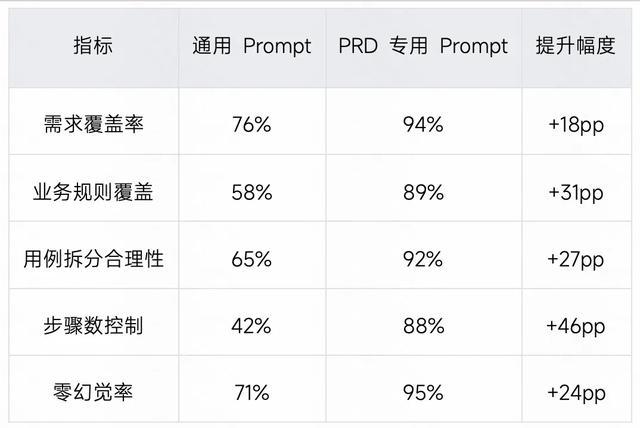
测试场景: 基于不同类型文档生成测试用例
对照组:通用 Prompt(不区分文档类型)
实验组: 场景化 Prompt(根据文档类型自动匹配专用模板)
场景 1:PRD 功能用例生成
典型改进案例:
场景 2:技术方案用例生成
典型改进案例:

3.1.4 核心问题
尽管经过多轮优化,V1.0 仍面临三大难以突破的瓶颈:
问题 1:长文档理解能力不足

问题 2:缺乏业务背景知识
问题 3:生成过程“黑盒”

3.1.5 阶段总结
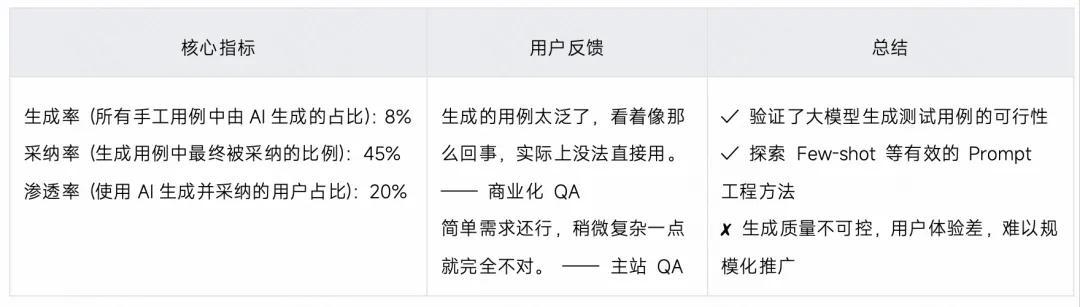
结论:需要从系统架构层面重新设计解决方案
3.2 V2.0 版本:Multi-Agent 协作与人机交互阶段
3.2.1 设计理念转变
QA 编写测试用例的真实思维过程并非“一步到位”,而是分阶段逐步推进的,具体如下:

QA 会先“拆解测试点(模块)”再“细化为具体用例”
每个阶段都存在 Review 环节,便于及时纠偏
若前期阶段出现偏差,后续将越走越偏
基于此,我们对于 V2.0 采用了新的设计思路,即模拟人类思维方式,引入 Multi-Agent 协作机制,并在关键节点支持人工介入。
3.2.2 Multi-Agent 架构设计
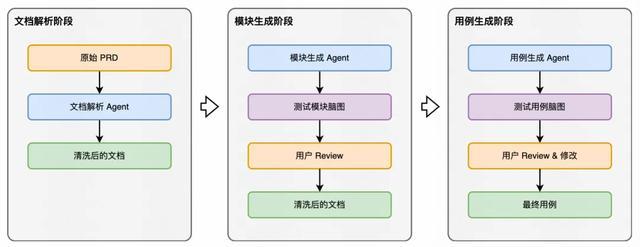
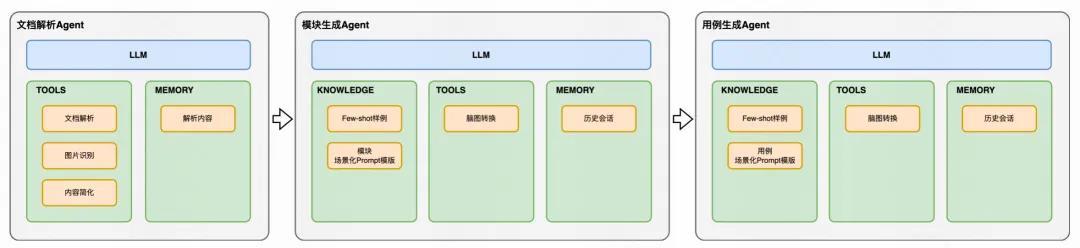
3.2.3 核心 Agent
文档解析 Agent
这一 Agent 的职责是,对多种格式的输入文档进行标准化处理,提取其中的有效信息。


模块生成 Agent
这一 Agent 的职责是从清洗后的文档中提取测试点,生成结构化的测试模块树。
用例生成 Agent
这一 Agent 的职责是,基于用户确认的测试模块,生成详细的测试用例。
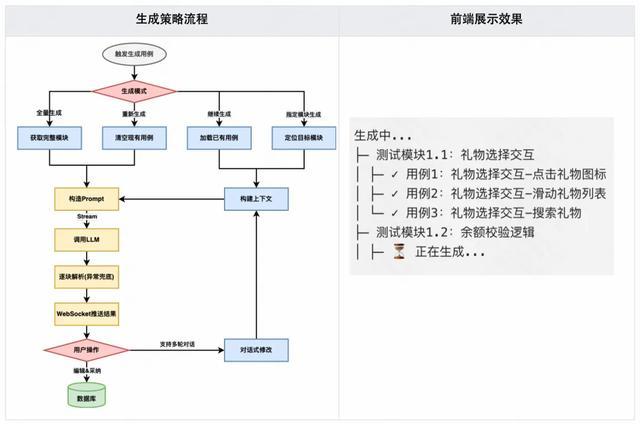
3.2.4 效果测评
为验证 Multi-Agent 架构与人机协作机制的有效性,我们针对 V2.0 版本的关键动作开展了基于真实业务场景的系统性测评,从多个维度对比 V1.0 与 V2.0 的表现差异。
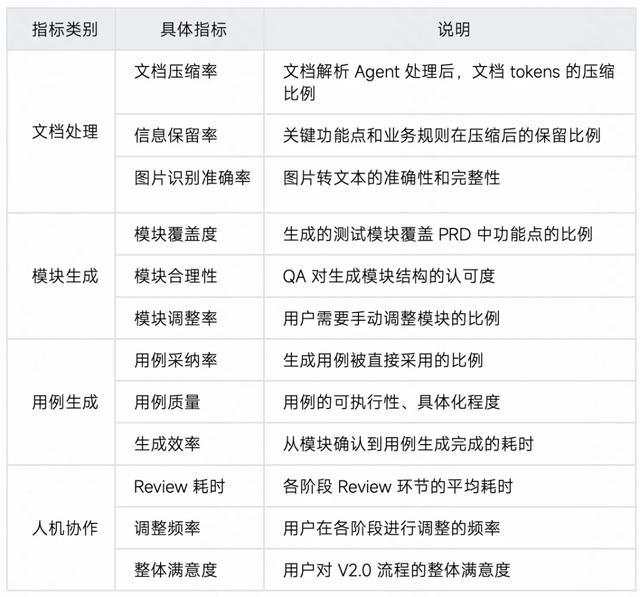
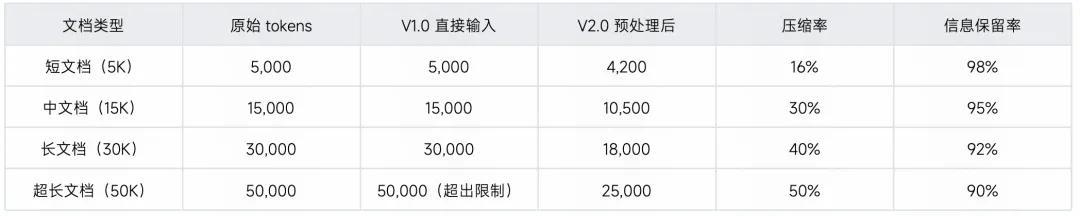
测评一:文档解析 Agent 效果验证
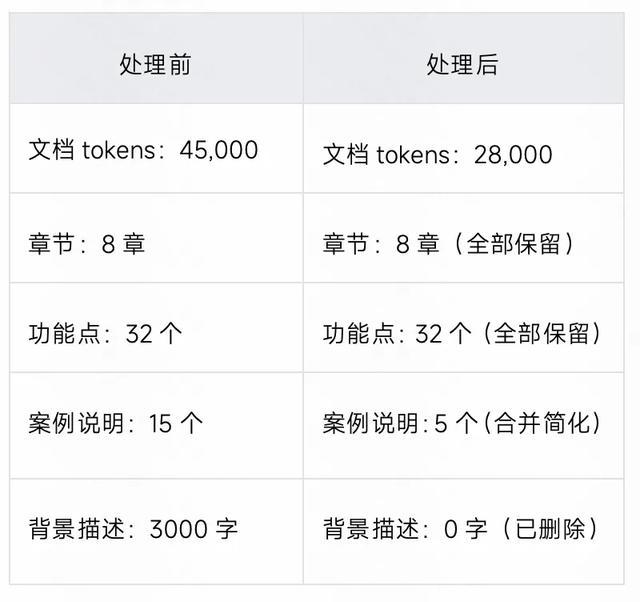
测试场景: 处理不同长度和复杂度的 PRD 文档
对照组:V1.0 直接输入完整文档
实验组:V2.0 经文档解析 Agent 预处理后输入
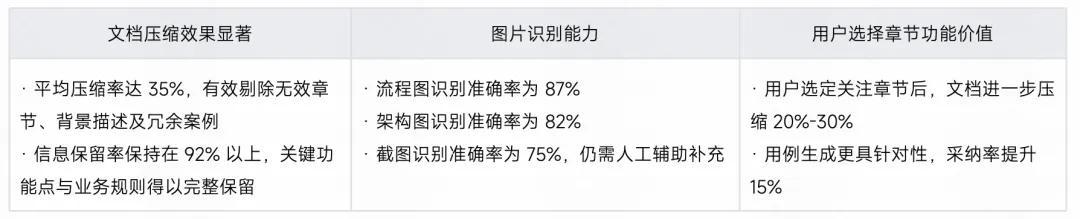
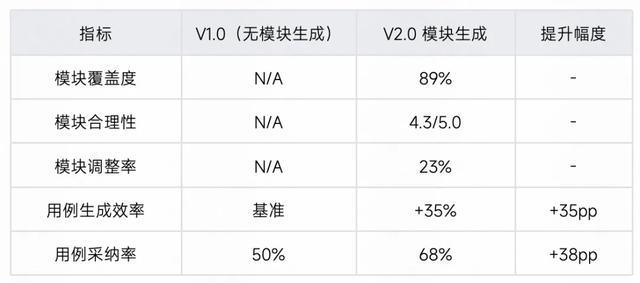
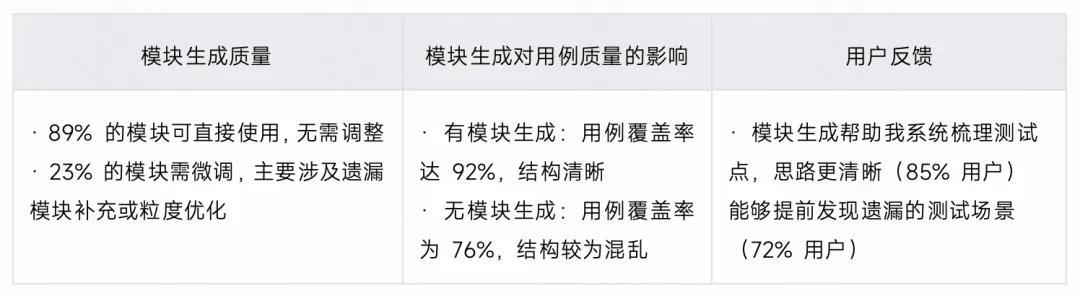
测评二:模块生成 Agent 效果验证
测试场景: 基于预处理后的文档生成测试模块树
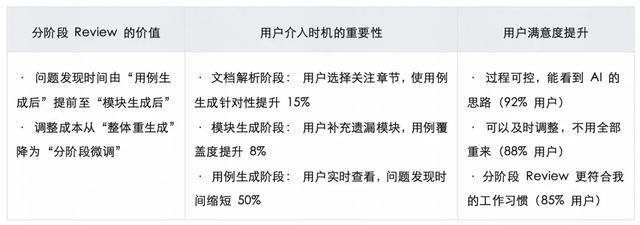
测评三:人机协作机制效果验证
测试场景: 对比 V1.0(黑盒模式)与 V2.0(分阶段 Review)的用户体验与效率
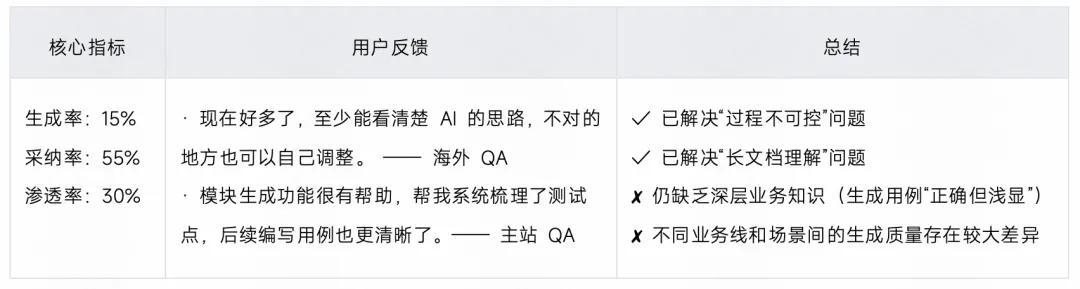
3.2.5 阶段总结
3.3 V3.0 版本:知识工程阶段
3.3.1 设计动机
我们发现,V2.0 遗留着一个核心问题,即生成的用例缺乏“业务深度”。

基于此,我们调整了 V3.0 的设计目标,即构建体系化的知识引入机制,使 AI 具备“懂业务”的能力。
3.3.2 架构设计
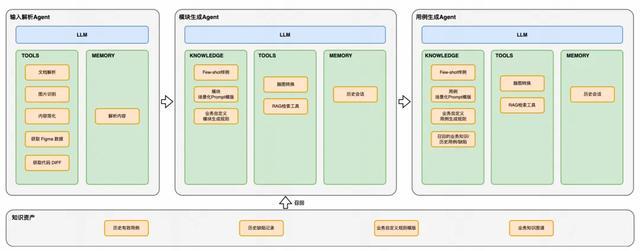
3.3.3 RAG 检索增强生成
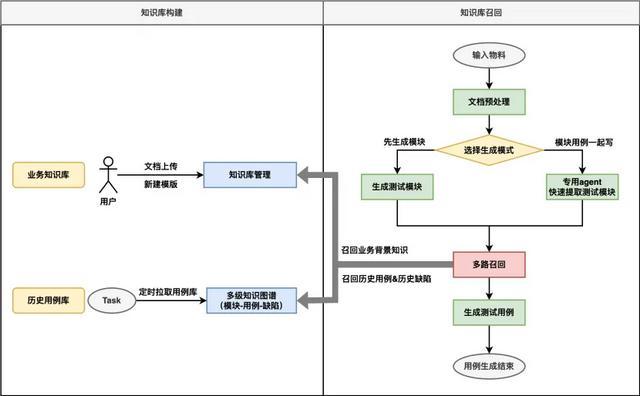
召回结果的价值:
提供了详细的步骤参考(如“URL 参数携带 need_amount”)
补充了业务规则(如“充值后自动返回”)
最重要:带入了历史缺陷经验(并发重复扣款、支付超时重复订单)
基于 RAG 增强的用例生成

3.3.4 效果测评
为验证体系化知识引入机制的有效性,我们针对 V3.0 的关键功能进行了基于真实业务场景的系统性测评,从多个维度对比 V2.0 与 V3.0 的表现差异。
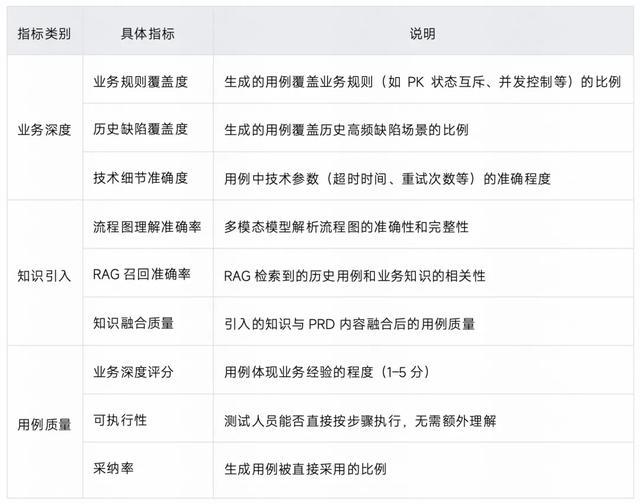
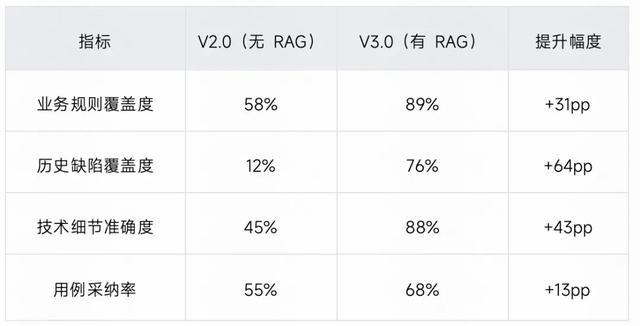
测评一:RAG 检索增强生成效果验证
测试场景: 基于 PRD 生成测试用例,对比有无 RAG 增强的效果
对照组:V2.0 仅基于 PRD + Few-shot 样例生成用例
实验组:V3.0 基于 PRD + RAG 检索的历史用例和业务知识生成用例
测评二:知识引入综合效果验证
测试场景: 对比 V2.0 和 V3.0 在整体用例生成质量上的差异
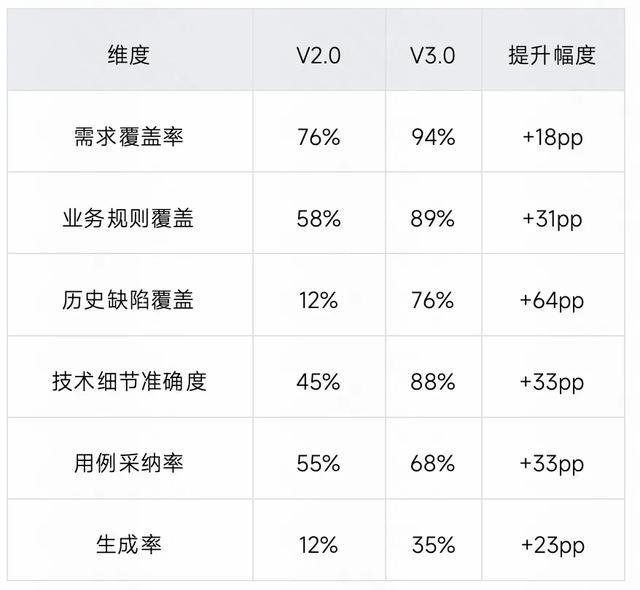
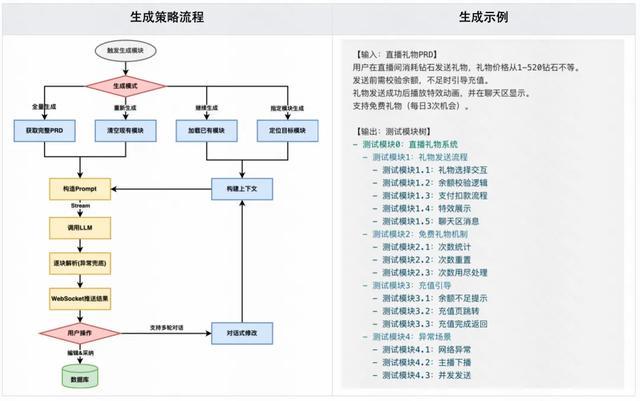
典型改进案例:【直播礼物需求】

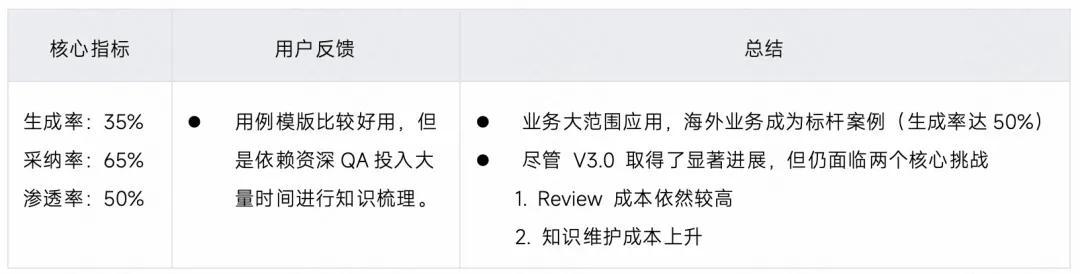
3.3.5 阶段总结
3.4 V4.0 版本:自主性 & 自进化阶段
3.4.1 技术架构
3.4.2 核心突破一:自主评审,Review-Critique 生成模式
传统的 AI 生成采用“单次直出”模式,类似于只会答题而不会检查的学生。为提升生成质量,需赋予 AI “自我反思”能力,构建“生成 - 评审 - 优化”的自主评审闭环机制。
关键设计理念:
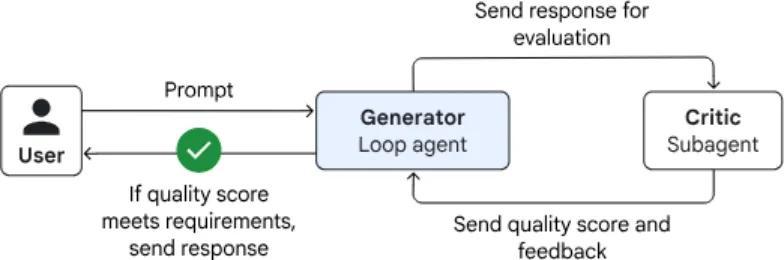
Critic(判别):AI 扮演“评审员”角色,对生成结果进行系统性审查并给出专业指导建议
Generator(生成):根据评审意见自动调整与优化输出内容
离线异步:因多轮迭代耗时较长,采用后台处理结合通知机制,保障效率与响应性
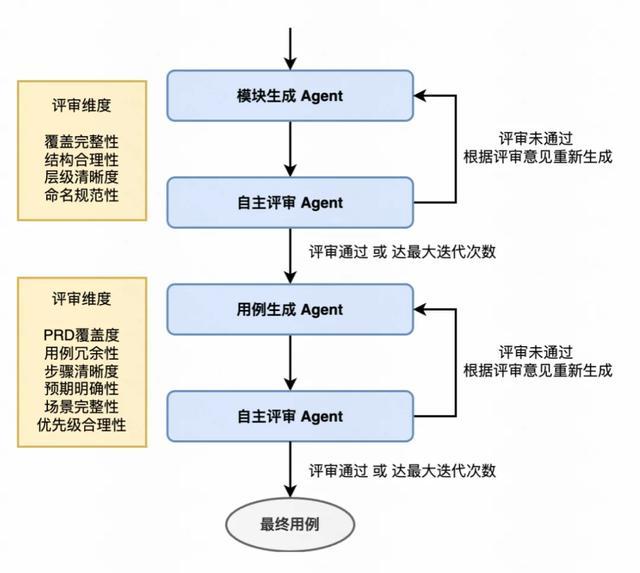
阶段一:模块级评审 ->优化闭环(结构治理)
自主评审 Agent —— 模块审查维度详解:
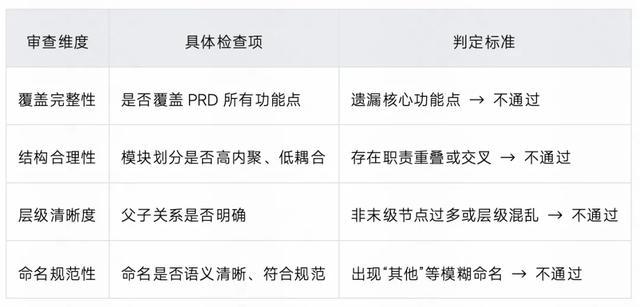
输出示例(未通过):

阶段二:用例级评审 ->优化闭环(细节打磨)
自主评审 Agent
用例审查策略:全局 Review + 逐条细节检查
用例审查维度:
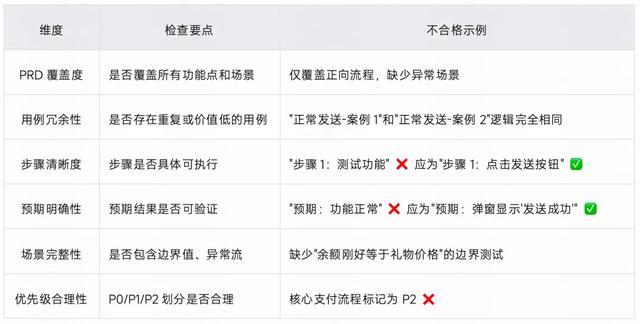
输出示例(未通过):

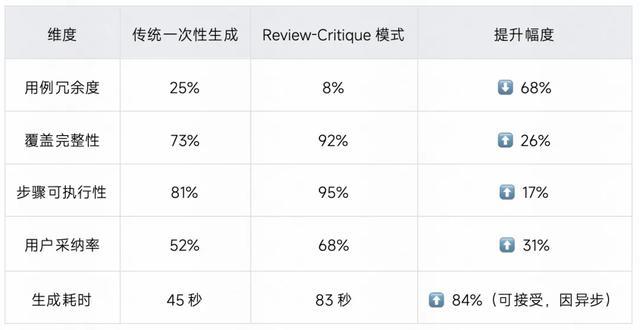
对比传统模式的提升:
3.4.3 核心突破二:基于测试计划的自进化场景规则模板
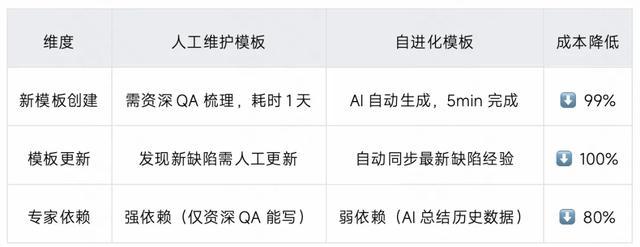
问题背景:知识维护的困境
在 V3.0 阶段,为了让 AI 理解业务,需人工编写大量团队业务模板(业务已维护 170+ 套业务定制的团队模板),但该模式存在三大痛点:
维护成本高:每个新业务场景均需人工梳理规则
知识更新慢:历史缺陷经验无法及时同步至模板
专家依赖强:需资深 QA 才能总结高质量模板
因此,我们的核心设计理念是让系统从历史数据中自动学习,实现隐性知识显性化。
技术方案:双层模板体系
我们构建了两种层级的自进化模板:
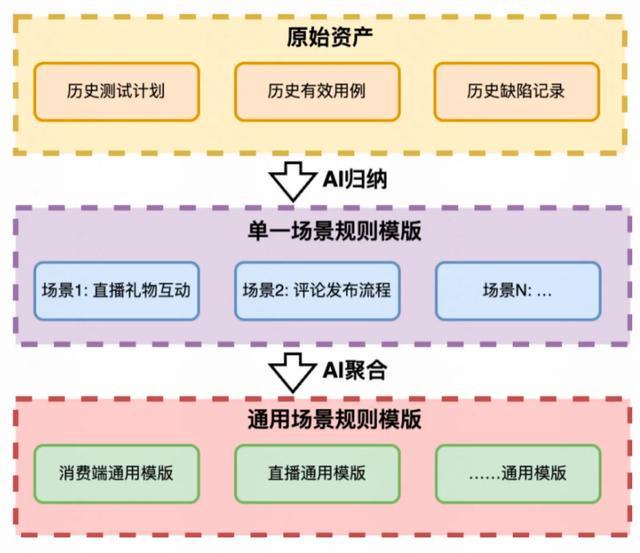
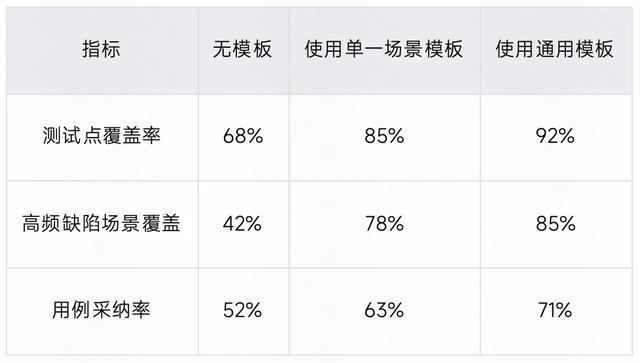
单一场景知识:精准规则提取
定位:针对特定微场景(如“直播间送礼”、“评论输入框”)的精确规则
作用:作为 RAG 链路中的上下文参考;自动补齐测试点,降低遗漏率
场景模版生成流程


通用场景模板:聚类与抽象
定位:多个相似场景聚合而成的通用规范(如“消费端评论发布通用模板”)
作用:支持手动召回的 RAG 链路;作为明确的生成规则,提升精度

AI 聚合核心逻辑:
提取共性:保留出现在两个及以上场景中的规则
去除个性:过滤仅属于特定需求的特殊逻辑
保留具体细节:避免笼统表述如“参考历史模板”,必须明确列出具体的验证点
核心价值与成效
3.4.4 阶段总结

实践 2: 四层架构驱动的方法论实践
图片
AI 测试用例生成系统的成功,往往依赖于一套分层递进的架构体系。基于此,我们在实践中提炼出“四层架构”模型:场景分层 → 用户运营 → 知识运营 → Agentic 架构,自上而下指导决策方向,自下向上提供能力支撑。
4.1 四层架构全景
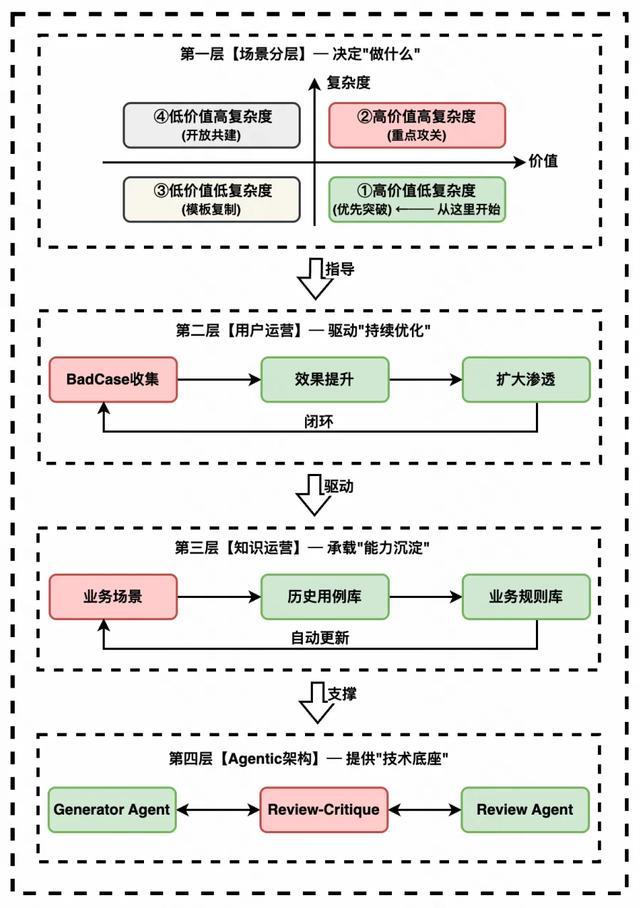
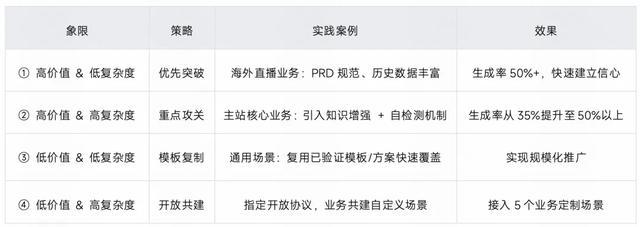
4.2 场景分层 —— 选对战场
我们的核心原则是不追求“全覆盖”,而是基于价值 x 复杂度矩阵进行精准突破。
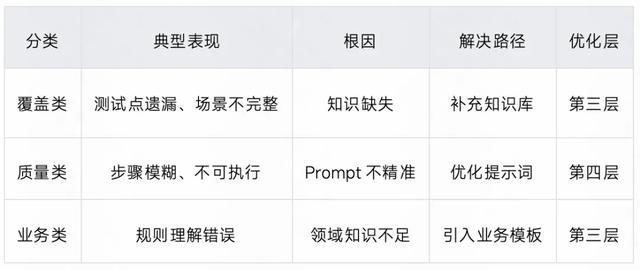
4.3 用户运营 —— Badcase 驱动闭环
Badcase 是最好的老师,通过系统化收集与分析用户反馈,驱动持续迭代优化。
Badcase 分类与解决路径

关键指标演进:
4.4 四层协同:从 Badcase 到系统进化
我们以一个 Badcase 如何驱动四层协同进化来示例。
【触发】用户反馈:直播送礼场景缺少“并发送礼”测试点
【第一层 - 场景分层】
判定:直播送礼属于“高价值”场景,值得深入优化
【第二层 - 用户运营】
Badcase 分类:覆盖类问题
根因分析:知识库缺少并发场景的历史缺陷数据
【第三层 - 知识运营】
补充缺陷库:新增“并发送礼重复扣款”历史 Bug 记录
更新规则库:提取“支付场景必须验证并发”规则
自动更新模板:直播送礼模板中新增并发测试点
【第四层 - Agentic 架构】
RAG 检索:后续生成自动召回并发相关知识
Critique Agent:自动检查是否覆盖并发场景
【结果】同类 Badcase 不再出现,场景覆盖率提升至 92%
4.5 方法论总结
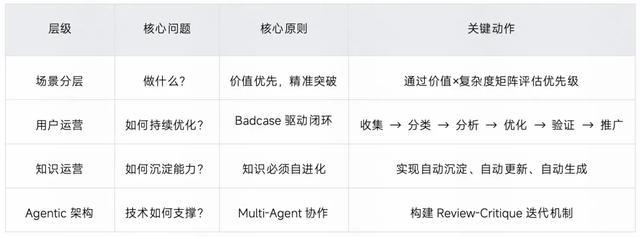
核心启示:
自顶向下做决策:通过场景分层明确资源投入方向,确保战略聚焦
自底向上建能力:以 Agentic 架构支撑知识运营,推动能力持续沉淀与复用
Badcase 是进化燃料:每个问题都是优化契机,形成“反馈→改进→提升”的持续进化飞轮
展 望
经过从 V1.0 到 V4.0 的持续演进,快手智能测试用例生成系统已完成了从「实验性工具」到「标准化生产力工具」的跨越。
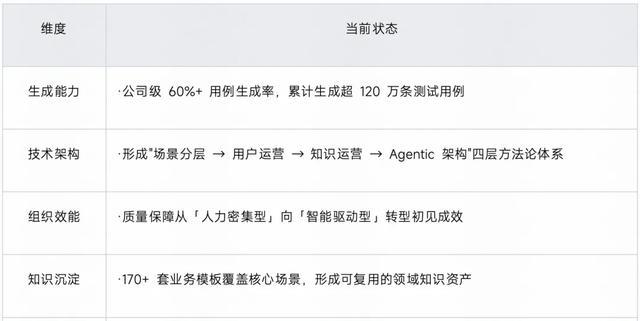
然而,我们也认识到,测试效率提升空间远不止于「生成」环节,测试人员仍需投入大量时间在手工用例执行上,这是下一阶段的核心突破方向。未来,我们将核心突破聚焦于「AI 智能执行用例」场景,构建从用例生成到用例执行的全链路智能化能力。
具体包含如下三个方向:

华融配资提示:文章来自网络,不代表本站观点。



沪深京行情 实时轮播
热点资讯
